"You start with a random clump of atoms, and if you shine light on it for long enough, it should not be so surprising that you get a plant."
Jeremy England (2014), interview commentary with Natalie Wolchover
Hace ya un mes que terminé de estudiar a fondo el interesante trabajo que el físico
Jeremy England está realizando en el
MIT (Massachusetts Institute of Technology). En mi blog he divulgado todo lo referente a este trabajo con mucho nivel de detalle, siendo
esta entrada un compendio de todo lo que el trabajo cuenta.
La idea de esta línea de investigación viene a decir, a
grosso modo, que
la física de nuestro mundo mantiene una
relación implícita entre
complejidad y energía. Esta relación indica que, cuanto más complejo es un fenómeno, más energía debe disiparse de modo que crezca la
probabilidad de que tal fenómeno finalmente acontezca. Esta teoría de
Jeremy parte, y se deduce, de una base termodinámica y de mecánica estadística ya establecida, por lo que sus conclusiones teóricas se toman ya por ciertas. El equipo simplemente necesita un mayor apoyo
experimental que respalde su propuesta, y yo creo haber conseguido aportar un granito de arena en este sentido, luego veremos cómo.
Desde el primer momento, la idea de esta investigación me atrajo sobremanera. Realmente es cierto que cualquier fenómeno complejo que observamos (y no sólo en el terreno biológico) es un gran devorador relativo de energía. Además, podemos ver que cuanto más complejo es un fenómeno, más energía parece necesitar para su formación y mantenimiento; siendo, por cierto, el fenómeno que más energía consume aquí en la Tierra, también el más complejo que observamos: el
sistema social humano.
La teoría de
Jeremy técnicamente se resume en la siguiente fórmula:
Es cierto que esta fórmula
intimida en un primer vistazo, pero es sólo porque normalmente no se conoce el significado de gran parte de los símbolos que se utiliza. Podéis ver el desarrollo completo que lleva a esta fórmula desde
esta entrada de mi blog. En realidad, con las matemáticas del bachillerato (y quizás un poquito más) es suficiente para seguir el proceso.
Esta
fórmula presupone su validez en un sistema físico muy determinado. Es decir; que para que se cumpla, debemos estar estudiando un sistema que cumpla lo siguiente:
Ser,
1) Un sistema lejos del
equilibrio térmico (como por ejemplo, la Tierra).
2) Poseer una fuente constante de
energía externa entrando en dicho sistema (como es el caso del Sol).
3) Y que posea también un gran baño térmico donde disipar calor (como es el caso de la atmósfera o el océano en la Tierra).
Todo sistema que cumpla estas tres condiciones, en
teoría debería evolucionar siguiendo la fórmula que acabamos de ver. Y la fórmula, a
grosso modo, nos indica la
probabilidad de observar determinados
fenómenos macroscópicos según sean sus propiedades físicas:
Los dos primeros términos de la fórmula, nos dicen que el sistema tiende espontáneamente hacia fenómenos macroscópicos
caóticos y sin orden; sistemas que son fácilmente
reversibles en el tiempo. Y esto es así por la sencilla razón de que hay más sistemas de este tipo: si
dividimos el conjunto de estados
posibles entre estados
desordenados y
caóticos, y estados ordenados que siguen un patrón; se puede comprobar que el primer subconjunto (el subconjunto que engloba los estados desordenados) contiene un número
astronómicamente mayor de
elementos que el subconjunto de estados
ordenados y
complejos.
Y este
dominio de estados
desordenados posibles sobre estados
ordenados posibles, es el que hace que la probabilidad de observar sistemas desordenados sea muchísimo mayor cuando se deja evolucionar
libremente sistemas físicos en el mundo. Esto lo expresa
matemáticamente la fórmula anterior con sus
dos primeros términos. El primero lo hace de un modo explícito, y el segundo término es consecuencia del primero: un sistema
reversible es más probable de observar, puesto que es más fácil de alcanzar. Y es que, si un sistema es poco reversible, es porque para ser alcanzado dicho sistema debe haber seguido un
patrón complejo (pasando por sucesivos estados del subconjunto mucho menos numeroso de estados posibles
ordenados).
El tercer y cuarto término de la ecuación, nos indican algo muy interesante: la
probabilidad de alcanzar fenómenos
complejos y
ordenados (que hemos visto que pertenecen al subconjunto de estados físicos
posibles astronómicamente menos numeroso) puede
aumentar, con tal de que la suma de estos dos términos aumenten en
proporción a la
complejidad que se quiere observar.
Es decir; que aunque el
subconjunto de estados ordenados sea enormemente reducido, es posible favorecer la probabilidad en la aparición de dichos fenómenos complejos, a
condición de que dicho fenómeno complejo consiga, o mejor dicho, que posea la
propiedad de ser
eficiente aumentando el
calor medio disipado en su formación y mantenimiento (el tercer y cuarto miembro de la ecuación reflejan precisamente esto: el
calor disipado de
media) .
Por lo tanto: la probabilidad de observar fenómenos complejos espontáneamente en estos sistemas lejos del equilibrio térmico es
prácticamente imposible (ya que, como hemos dicho, el subconjunto de estados ordenados posibles es
inmensamente menor en tamaño al de estados desordenados posibles) a menos de que el tercer y cuarto término (el
calor medio disipado) sea lo suficientemente
alto como para
compensar el bajo valor de los dos primero térmicos (bajo valor que hemos visto es consecuencia de la supremacía de estados desordenados hacia los que puede ir el sistema).
Bien. Esto es la
teoría, y además es una
teoría contrastable. De hecho, los chicos del
MIT ya han encontrado respaldo en ciertos experimentos realizados, aunque aún nada determinante. Yo, por mi parte, creo haber encontrado un modo de apoyar la teoría de
Jeremy England haciendo uso de lo que es mi área de estudio: la
computación.
Objetivo del trabajo.
Es muy complejo respaldar directamente en un
laboratorio esta teoría, puesto que para estudiar la posible relación entre complejidad y calor disipado, en principio habría que estudiar un sistema
lejos del equilibrio térmico, y comprobar la relación entre la complejidad de lo observado con el calor que disipó su formación. El problema principal que yo veo, es que si se quiere estudiar sistemas complejos
reales que surjan espontáneamente en un laboratorio, y si la relación entre complejidad y baja probabilidad de ocurrencia es cierta, habría que esperar
cientos de miles de horas (o años) para que finalmente ocurra dicho fenómeno (y calcular el calor disipado). Es decir; y para poner un
ejemplo extremo que clarifique el problema: si ponemos en una maceta todos los componentes individuales necesarios para formar una planta y lo dejamos reposar al Sol, necesitaríamos de millones de años para que la compleja planta se formara al azar y medir así el calor disipado: no es práctico (xDD). Se podría, evidentemente, intentar estudiar de este modo fenómenos menos complejos (y por lo tanto más probables) que una planta, pero el problema es que cuanto menos complejo sea el fenómeno, menos evidente va a ser la correlación entre calor y complejidad (ya que ésta va a ser menor), y cualquier correlación observada (al ser débil) se podría achacar a
otros factores ambientales o a errores de medición.
En realidad hay otros métodos
menos directos de contrastar esta teoría, y me consta que el
equipo de
Jeremy está en ello, pero desde el principio se me ocurrió un modo de poder estudiar el asunto desde esta perspectiva más directa de la que hablo: utilizando la
simulación por ordenador.
¿En qué consiste mi prueba experimental?
La idea es la siguiente:
1) Programamos un sistema físico que simule lo mejor posible la realidad física.
2) Programamos un modo de calcular la energía del sistema conforme el sistema evoluciona en el tiempo.
3) Procedemos a
buscar sistemas complejos mediante
computación evolutiva.
4) Calculamos el calor disipado en la formación de tales sistemas ordenados.
5) Estudiamos si existe correlación en esta simulación, entre la complejidad alcanzada y el calor disipado.
Y para reforzar aún más el estudio experimental, procedemos de nuevo, pero sustituyendo el paso 3) y 4) por lo siguiente:
3) Procedemos a
buscar sistemas que disipen poco calor mediante
computación evolutiva.
4) Calculamos la complejidad del sistema cuando se disipa poco calor.
Si la
correlación propuesta entre complejidad y calor disipado es correcta, los sistemas complejos deberán de ir
siempre (en la práctica) acompañados de una gran cantidad de calor disipado (energía útil consumida).
¡Y es precisamente esto lo que he observado cuando he realizado este experimento!
¿Cómo he procedido a realizar la prueba?
Para el punto
1) y 2) me ayudé de una librería de Java llamada
Opensourcephysics. Esta librería (de
código abierto) ha sido realizada precisamente para ayudar en la
simulación de sistemas físicos.
En concreto, partí de la simulación que incluye el paquete (en
org.opensourcephysics.sip.ch08.md) de sistemas de
potencial de Lennard-Jones. El potencial
Lennard-Jones es usado muy
comúnmente en la simulación por ordenador debido a que es una buena aproximación a la física de partículas real, y a que, aún siendo un modelo simple, permite un detallado estudio de las propiedades de los gases y de las interacciones en modelos
moleculares.
Esta librería de Java ya incluía pues lo que necesitaba para comenzar a experimentar: una simulación física bastante aproximada, pero a la vez lo más sencilla posible. Por cierto que la simulación del
potencial L-J que incluye
Opensourcephysics fue desarrollado originalmente en el 2006 por
Jan Tobochnik, Wolfgang Christian, y Harvey Gould.
Así que sobre la simulación de estos sistemas comencé a trabajar y a programar el resto de la prueba.
Lo primero que hice fue implementar uno de los requisitos que la teoría requiere: que el sistema sea expuesto a una fuente de energía externa constante. ¿Cómo lo hice? Pues simplemente simulando que el sistema
L-J está bajo una lluvia constante de partículas externas que eventualmente pueden
chocar con las partículas del sistema haciéndoles cambiar el
sentido de su
movimiento en las coordenadas
x e
y. Esta lluvia de partículas virtuales añadidas (emulando a la lluvia de
fotones que llegan desde el Sol a la Tierra) tras ocasionalmente golpear e interactuar con las partículas de nuestro sistema, simplemente desaparecen.
Ahora ya tenía lista una simulación bastante aproximada a la realidad física, y que cumplía las tres condiciones previas de la propuesta
teórica de
Jeremy England.
Paso 3): ¿Por qué introducir un algoritmo de computación evolutiva?
Si me hubiese limitado a observar como evoluciona
espontámente este sistema
L-J modificado, me habría encontrado en la misma situación, y con el mismo problema, que en el laboratorio: tener que esperar una enorme cantidad de tiempo hasta que diese la causalidad de que un
fenómeno complejo aconteciera en la
simulación física para poder calcular así el calor disipado.
En el mundo real no podemos acelerar artificialmente la ocurrencia de tal complejidad, por ejemplo en una matraz o en una placa de Petri, pero; y aquí viene la clave del asunto, en nuestra simulación sí que podemos
buscar o
dirigir el sistema hacia la complejidad de un modo
intencionado, acortando enormemente
el tiempo de espera necesario para que surjan patrones complejos y ordenados. ¿Y de qué modo es posible tal búsqueda capaz de lograr alcanzar la complejidad en un corto espacio de tiempo (en comparación con el tiempo necesario para que ocurra por azar)? Pues sí, como no: mediante un
proceso evolutivo. En concreto, hice uso de las propuestas de la
computación evolutiva (puedes ver algunas entradas donde trato sobre algoritmos evolutivos
aquí).
Esa fue la razón de añadir el tercer paso comentado: lograr, mediante un
proceso evolutivo computacional, observar patrones y sistemas complejos en nuestra simulación sin tener que esperar todo el tiempo que sería necesario para que la complejidad ocurriera de forma espontánea. Además, actuando de este modo, vamos a poder
dirigir el sistema hacia sistemas con las propiedades deseadas en cada caso; lo que nos permitirá estudiar más fácilmente si existe o no
correlación entre orden y consumo de energía.
Medición de la complejidad.
En este punto se presenta un problema: ¿cómo
medir o
calcular la complejidad de un sistema determinado? Para solucionar este problema, simplemente hice uso del sentido común. La presencia de patrones, agrupaciones, y orden de cualquier tipo es signo
evidente de complejidad (ya que dichos estados son pocos numerosos de entre todas las posibilidades físicas); por lo que, un modo sencillo de medir la complejidad, consiste en simplemente estudiar la cercanía entre cada par de partículas. Cuanto más
cercanas estuvieran las partículas entre sí; menos reversible será el sistema en el tiempo respecto al estado de partida (
segundo término con un bajo valor), y, además, existirán muchas menos configuraciones posibles con todas las partículas cercanas, que configuraciones con las partículas distribuidas al azar (lo que implica un bajo valor para el
primer término).
Hay que aclarar aquí, que aunque se utilice un proceso evolutivo para lograr alcanzar estados complejos en cortos periodos de tiempo; eso no implica que se alcanzará cualquier tipo de sistema, sino que el algoritmo evolutivo va a encontrar aquellos estados
más probables o
fáciles de alcanzar. Y resulta que, según la teoría de
Jeremy, los sistemas más probables (cuando los dos primeros términos tienen bajo valor) son aquellos sistemas que
disipan gran cantidad de calor en el proceso. Por lo tanto, una vez finalizado el proceso evolutivo (tras pasar las
n generaciones programadas), se habrán seleccionado aquellos estados más complejos pero también aquellos más
accesibles (y fáciles de alcanzar), los cuales; según la teoría, deberán ser aquellos que mejor se
adapten a la fuente de energía externa para realizar
trabajo (y consumir energía útil disipando gran cantidad de calor).
Resultados del estudio I.
En el primer caso de estudio, vamos en
3) a
dirigir el sistema evolutivamente hacia sistemas complejos (con todas sus partículas lo más cercanas posibles unas de otras), y procederemos a estudiar el calor disipado en el proceso:
En este estudio vamos a trabajar con
N = 25
partículas, moviéndose en una superficie (
bidimensional) de longitud
Lx = 25 y
Ly = 20. Esta superficie
no tiene
fronteras, lo que significa que, por ejemplo; la partícula que salga por la derecha, entrará por la izquierda a la misma altura (la Tierra es un sistema sin fronteras de este estilo, sólo que tridimensional y en forma de esfera). Se ajusta, además, una
energía cinética inicial por partícula igual a la unidad.
El algoritmo evolutivo procederá utilizando una población constante de i = 250 sistemas L-J (individuos), y durante g = 1250 generaciones antes de parar (condición de parada t > g). Cada 100 pasos (1 segundo aproximadamente), se evaluará la complejidad de cada individuo (como de cerca están sus partículas), y se seleccionarán aquellos individuos más adaptados (es decir, aquellos más complejos). De cada superviviente se creará un clon, y se aplicará una mutación, la cual consiste simplemente en aplicar el campo de fuerza externo del que hablamos antes (la lluvia de fotones virtuales que pueden eventualmente cambiar la dirección y sentido de algunas partículas del sistema).
Los sistemas que presenten la propiedad de ser los que mejor se adaptan a esta lluvia de fotones virtuales de modo que permitan la aparición de la complejidad buscada, serán los que vayan sobreviviendo al proceso. De este modo, se consigue que al finalizar la búsqueda evolutiva, obtengamos una población de sistemas L-J, cuyas trayectorias han ido siguiendo caminos poco reversibles y complejos, y al mismo tiempo adaptados a la fuente de energía externa.
Según la teoría, todos estos sistemas complejos finales deben haber disipado una enorme cantidad de calor para ser alcanzados (recordemos que el algoritmo evolutivo va a encontrar los sistemas complejos más probables), lo que se traduce en que la energía útil final de los individuos complejos debe ser mucho menor que la energía útil que tendría el mismo sistema original si no se hubiese guiado hacia la complejidad.
Veamos que ocurre al poner en práctica este experimento:
Para aclarar los resultados, hay que tener en cuenta que todo el proceso evolutivo comienza con i = 250 clones perfectos de un sistema aleatorio original al que denominamos Sistema Lennard-Jones I (o mdI para abreviar). Este sistema L-J de inicio (mdI) lo haremos evolucionar junto a la población pero sin ser guiado evolutivamente: es decir; que se le permitirá moverse durante los mismos pasos que a los individuos evolucionados, para que nos sirva así de sistema de control con el que comparar respecto al calor que disipa un sistema poco complejo de un modo natural.
Al finalizar el proceso evolutivo, vamos a seleccionar el mejor individuo de la población final de 250 supervivientes de sistemas L-J (es decir, el más complejo). A este individuo seleccionado lo llamaremos Sistema Lennard-Jones II (o mdII para abreviar).
Una vez tenemos a mdI y a mdII, tendremos ya dos sistemas que habrán recorrido el mismo número de pasos, pero que han seguido trayectorias diferentes en cuanto a complejidad. mdI habrá seguido trayectorias probables y espontáneas dominadas por los dos primeros términos de la ecuación de Jeremy, mientras que mdII habrá seguido caminos cada vez más complejos e irreversibles. Si la teoría del equipo del MIT es cierta, mdII debe haber disipado mucho más calor que mdI en el mismo número de pasos (el mismo intervalo de tiempo acontecido). Además, deberá existir una correlación directa entre complejidad y calor disipado, de modo que cuanto mayor complejidad conseguida por el proceso evolutivo, menos energía final tendrá el sistema (más calor disipó en su trayectoria).
Veamos los resultados:
Antes de nada, os muestro un
vídeo animado de lo que es la evolución temporal natural de un sistema
L-J como el que estamos estudiando. Como se puede observar, los estados que aparecen son poco complejos y pertenecen al grueso del numeroso subconjunto de estados posibles
desordenados. Para ver algún tipo de complejidad aparecer espontáneamente en este sistema, tendríamos que esperar probablemente muchos años:
Sistema Lennard-Jones I (mdI) sin dirigir
A continuación, podéis ver una imagen con el estado inicial
mdI, y el mismo estado inicial una vez que éste ha sido dirigido hacia un estado complejo (
mdII):
 |
Sistema Lennard-Jones I (mdI) tras
125000 pasos (125 segundos aprox.) |
 |
Sistema dirigido Lennard-Jones II (mdII) tras
los mismos 125000 pasos
(125 segundos aprox.) |
Como se puede observar, hemos conseguido que el
sistema L-J alcance una complejidad que podríamos estar años esperando que ocurriera de forma natural. Y, lo que es más importante ¡la complejidad alcanzada es poco reversible tal y como
Jeremy England afirma en sus estudios! Según la teoría, una vez se alcanza tras un periodo de tiempo una gran complejidad gracias a una alta disipación de calor, es
muy poco probable que el proceso inverso ocurra en el
mismo intervalo de tiempo. Os muestro a continuación un vídeo donde podréis observar como el estado
mdII, una vez el algoritmo evolutivo deja de actuar, no vuelve rápidamente a un estado más desordenado, sino que permanece mostrando el patrón ordenado que ya alcanzó:
Paso 5) Estudio de la correlación entre calor disipado y nivel de complejidad alcanzado.
Como ya se ha comentado, la complejidad se mide según sea la distancia entre cada par de partículas. Para que el proceso evolutivo pueda distinguir entre los mejores individuos de la población de
sistemas L-J, se va estudiando la complejidad
media alcanzada en un número de pasos dados:
Complejidad media alcanzada = complejidad / número de pasos
donde la
complejidad es simplemente la suma de la distancia de cada par de partículas.
Los valores de esta Complejidad media alcanzada van a ir tendiendo a cero conforme la complejidad aumenta en el tiempo, puesto que el número de pasos (
denominador) va aumentando mientras que la suma de complejidad (
numerador) llega un momento que apenas aumenta. Los valores de la complejidad media serán tanto mejores cuanto más cerca del cero se encuentre. Una complejidad media de
0,5 viene a representar un estado que ha evolucionado de un modo totalmente
caótico con las partículas esparcidas de un modo más o menos homogéneo por toda la superficie.
Para más claridad, y antes de mostrar la tabla de resultados, voy a mostrar la apariencia final según la complejidad alcanzada en el proceso dirigido en varios
sistemas L-J:
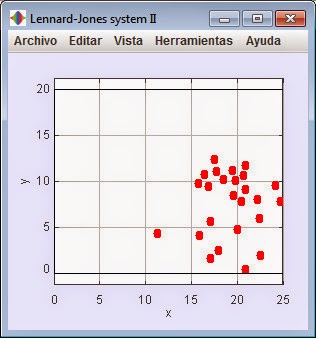 |
Apariencia de sistema L-J (mdII) con una complejidad
media conseguida de 0.20 |
Evolución posterior de este sistema L-J (mdII) con una
complejidad media conseguida del 0.20
 |
Apariencia de sistema L-J (mdII) con una complejidad
media conseguida de 0.04 |
 |
Apariencia de sistema L-J (mdII) con una complejidad
media conseguida de 0.065 |
 |
Apariencia de sistema L-J (mdII) con una complejidad
media conseguida de 0.060 |
Evolución posterior de un sistema L-J (mdII) con una complejidad
media conseguida de 0.060
Medición del calor disipado.
El calor disipado lo vamos a medir simplemente tomando la energía inicial (suma de energía cinética y potencial) y restando la energía final. Esta diferencia en la energía va a
representar el
calor que se disipado en el proceso. Calor disipado que, según la teoría, debe ser tanto mayor, cuanto mayor complejidad se alcance.
Mostramos a continuación la
tabla de resultados del calor
disipado (tras 125000 pasos
) según el nivel de complejidad medio alcanzado, y comparado en relación a un sistema de
control. El sistema
L-J de control, como hemos visto, no es más que el mismo sistema inicial
mdI pero que procede el mismo número de pasos que
mdII aunque sin ser dirigido:
Complejidad mdII: Energía final mdI: Energía final mdII: Calor disipado (mdI - mdII):
0.410 2665936.29 2651880.45 14055.84
0.195 2633071.24 951213.39
1681857.84
0.064 2680313.52 634706.74 2045606.77
0.060 2687338.15 -1169582.75 3856920.91
0.051 2697423.30 -506615.05 3204038.36
¡¡Se puede ver una indudable correlación entre la complejidad media del sistema y calor disipado en el proceso!!
Pero para reforzar más estos datos, vamos a proceder a continuación a mostrar un seguimiento de la evolución en las 1250 generaciones del
mejor individuo, realizando una comparación como la anterior donde veremos la relación entre el calor disipado en cada generación con la complejidad alcanzada hasta ese momento. La
correlación entre complejidad y cantidad de calor disipado es innegable:
Generación Complejidad mdII: Energía mdI: Energía mdII: Calor disipado (mdI - mdII):
125 2.578 291576.44 162282.31 129294.12
250 1.194 558308.67 221265.40 337043.27
375 0.475 829178.78 203825.56 625353.22
500 0.301 1075901.39 22840.16 1053061.22
625 0.141 1339369.76 -210296.34 1549666.10
750 0.145 1605291.85 -445750.92 2051042.77
875 0.112 1866449.60 -669400.96 2535850.56
1000 0.151 2142136.75 -885776.27 3027913.02
1125 0.108 2415270.38 -1108760.68 3524031.06
1250 0.055 2679966.69 -1350419.40 4030386.10
La
correlación es más que
evidente comparando los valores de la columna de complejidad
mdII con la columna del calor disipado. A mayor complejidad (cuanto más cerca de 0 está el valor) mayor calor disipado con respecto al sistema de control
mdI (que mantiene su complejidad
muy baja en el tiempo).
 |
| Sistema inicial mdI de la tabla anterior |
 |
| Sistema mdII de la tabla anterior tras las 1250 generaciones |
Complejidad irreversible.
Si, una vez alcanzado un estado
complejo, dejamos a continuación evolucionar el sistema
libremente; tal y como afirma la teoría,
no se vuelve
instantáneamente al desorden, sino que el orden conseguido se mantiene conforme pasa el tiempo. Al haberse liberado mucho calor y haberse consumido mucha energía útil, las matemáticas del estudio nos cuentan que el proceso alcanzado va a ser bastante
irreversible en el mismo
periodo de tiempo invertido
¡y eso es lo que se observa! Os dejo a continuación un vídeo donde se observa la evolución de un sistema
mdII de alto nivel de complejidad alcanzado. Podéis ver como aún pasando mucho tiempo, la agrupación de las partículas se mantiene, formándose diversos tipos de patrones y agrupaciones (e incluso órbitas):
Es más, conforme el sistema complejo sigue evolucionando
libremente, ¡se puede comprobar como
sigue disipando mucha más energía que el sistema caótico de control! Cosa que sigue estando de acuerdo con la teoría de
Jeremy England, puesto que la complejidad, para permanecer en el tiempo, requiere de una constante disipación de calor que contrarreste la
irreversibilidad y la baja probabilidad de su
complejidad.
Anotaciones sobre el estudio:
No nos llevemos a engaño. El uso de un
algoritmo de computación evolutiva
no interfiere directamente en el modo en que el sistema cambia en el tiempo, sino que simplemente es una herramienta que nos ayuda
a buscar de entre todas las posibles trayectorias naturales, aquellas que conducen a patrones complejos sin la necesidad de tener que esperar años a que esto ocurra de un modo natural. Es sólo un modo de disminuir exponencialmente el tiempo requerido para poder estudiar sistemas complejos que son poco probables de acontecer espontáneamente, pero lo hace sin interferir directamente en el desarrollo del sistema físico: se trata sólo de
ver y
seleccionar lo que nos interesa, desechando las alternativas que son poco prometedoras como candidatas a finalizar en sistemas complejos.
Es decir; que es muy importante comprender que, pese al uso del algoritmo evolutivo, los datos obtenidos, y que se han mostrado en las tablas anteriores, son exactamente los mismos que obtendríamos si esperásemos durante años hasta que un estado complejo del estilo que hemos estudiado apareciera de un modo natural y espontáneo.
Resultados del estudio II.
En este segundo caso de estudio, vamos en el paso
3) a
dirigir el sistema evolutivamente, no hacia sistemas complejos somo hicimos antes, sino hacia sistemas que disipen poca cantidad de calor. Si la teoría que pretendemos corroborar es cierta, también debería observarse una correlación entre un menor consumo de energía y una menor complejidad:
Vamos a trabajar aquí también con N = 25
partículas, moviéndose en una superficie (bidimensional) de longitud
Lx = 25 y
Ly = 20.
Para realizar este estudio, vamos a partir de un
sistema L-J muy complejo (
mdII), y a observar qué ocurre si
dirigimos este sistema hacia bajos niveles de calor disipado (valores bajos del tercer y cuarto término). La teoría afirma que, puesto que comenzamos en un estado muy ordenado (primer y segundo término bajo), la probabilidad de
observar tal complejidad con cierta frecuencia ha sido respaldada por una alta disipación de energía previa. Si ahora
buscamos sistemas que partan de este sistema complejo (
mdII) pero que cada vez disipen
menos calor, debe ocurrir la correlación
inversa a la del
estudio I: cuanto menos calor disipe el camino o
trayectoria, más complejidad debe
haber perdido (más debe haber
subido el primer y segundo término para respaldar la bajada en los términos tercero y cuarto).
Así, si partimos de un sistema complejo y este sistema empieza a disipar menos calor, debe ser a costa de
disminuir su complejidad.
Técnicamente, este estudio lo he realizado del siguiente modo:
1) Procedemos como en el
estudio I buscando sistemas complejos en 1250
generaciones (125000 pasos) a partir de un sistema origen
mdI.
2) Seleccionamos el mejor individuo de la población final (
mdII) y medimos el calor disipado y la complejidad alcanzada.
3) Procedemos a
buscar evolutivamente sistemas con
bajo calor disipado a partir del anterior mejor individuo
mdII. Tras otras 1250 generaciones (otros 125000 pasos), seleccionamos al mejor individuo de la población final (
mdI*).
4) Medimos la complejidad de
mdI* y el calor disipado, y comparamos con el sistema de control (
mdII) el cual habrá dado también 125000 pasos pero sin ser dirigido a menores niveles disipativos.
Si la teoría es correcta, el sistema
mdI* deberá poseer unas características muy similares al
mdI original en cuanto a
complejidad se refiere.
Mostramos a continuación los
resultados de este
estudio:
Complej. mdI: 0.345 Energía mdI: 2663414,03
Complej.mdII: 0.063 Energía mdII: -535605,01 Disipado (mdI - mdII): 3199019,04
Complej.mdI*: 0.401 Energía mdI*: 3135984,42 Disipado (mdII - mdI*): -3671589.43 (el sistema no consume y disipa energía útil, sino que la adquiere)
Se puede
observar como una
disminución en el calor disipado (la energía útil consumida) va acompañada de un
descenso en la complejidad, como se pretendía comprobar.
En las siguientes
instantáneas se puede observar como evoluciona el sistema cuando primero alcanza gran complejidad mediante el uso de mucha energía, y de como el sistema vuelve a perder complejidad estructural en cuanto el calor disipado disminuye en el tiempo:
 |
| Sistema aleatorio original mdI |
 |
Sistema final mdII tras las primeras 1250 generaciones
buscando alta complejidad. Este sistema es el que
usamos para buscar a partir de él alta disipación |
 |
El mismo sistema mdII tras haber servido de control
moviéndose libremente 125000 nuevos pasos |
 |
Sistema final mdI* tras buscarse durante 1250
generaciones a partir de mdII sistemas que
disipen poca cantidad de calor. Se puede observar
como la complejidad se pierde |
Y para terminar, sólo señalar que, si repetimos este último experimento pero procedemos a partir de
mdII a
buscar evolucitvamente sistemas que disipen
más calor (en lugar de menos como antes), también vemos como el sistema se ajusta a lo que la teoría predice: el sistema final
mdI* tras las 2500 nuevas generaciones va a ser de una complejidad similar a
mdII:
Complej. mdI: 0.412 Energía mdI: 2637496.65
Complej.mdII: 0.058 Energía mdII: -458086.05 Disipado (mdI - mdII): 3095582.70
Complej.mdI*: 0.046 Energía mdI*: -3359158.03 Disipado (mdII - mdI*): 2901071.98
 |
| Sistema aleatorio original mdI |
 |
Sistema final mdII tras las primeras 1250 generaciones
buscando alta complejidad. Este sistema es el que
usamos para buscar a partir de él alta disipación. |
 |
El mismo sistema mdII tras haber servido de control
moviéndose libremente 125000 nuevos pasos |
 |
Sistema final mdI* tras buscarse durante 1250
generaciones a partir de mdII sistemas que
disipen alta cantidad de calor. Se puede observar
como la complejidad se mantiene e incluso
aumenta en este caso |
Vídeo que muestra el movimiento libre de un sistema mdI* tras haber sido
evolucionado buscando complejidad 1250 generaciones a partir de mdI,
y haber sido más tarde evolucionado buscando alta disipación de calor otras
1250 generaciones a partir de mdII
Este último ejemplo demuestra como, una vez un sistema complejo ha sido alcanzado, el mantenimiento o el aumento en el calor disipado sólo es posible si se mantiene la complejidad; siendo muy poco probable que la complejidad caiga y aún así se disipe más. El ejemplo anterior nos mostró el caso opuesto, como una vez alcanzada la complejidad se requiere mantener el nivel de calor disipado para mantener la complejidad, siendo muy poco probable que la complejidad se mantenga y el calor disipado descienda.
Conclusión.
Mediante este
doble estudio
experimental se ha podido corroborar en sistemas físicos simulados mediante sistemas de
potencial de Lennard-Jones la propuesta teórica de
Jeremy England. Ciertamente hemos observado una
correlación muy clara entre calor disipado (energía consumida por un trabajo) y complejidad estructural. Además, dicha correlación se da tanto si se
buscan sistemas complejos (en cuyo caso se observa que el calor disipado es mucho mayor del normal), como si se
buscan sistemas que disipen poco calor (en cuyo caso se observa una disminución en la complejidad estructural y un aumento del desorden).
Todo esto parece
apoyar sin duda la
teoría matemática que precisamente se fundamenta en lo que acabamos de decir: que los fenómenos físicos complejos sólo son
asequibles estadísticamente si sus propiedades los hacen buenos disipando gran cantidad de calor (ya que eso aumenta su probabilidad de ocurrencia). En otras palabras: un sistema complejo cuyas propiedades
no lo hagan eficientes consumidores de energía, es casi imposible que
acontezca de un modo espontáneo; pero sin embargo, si las propiedades de este sistema lo hacen eficientes consumidores de energía, la física del mundo hará que la probabilidad de ocurrencia de tal complejidad sea mayor que en el caso contrario.
Esto
no implica en absoluto que la complejidad surja por doquier sino que nos aclara que, cuando surge, es porque la
probabilidad de tal complejidad ha aumentado lo suficiente (dada la oportunidad) gracias al tercer y cuarto término del que hemos hablado. Por lo tanto, conforme el tercer y el cuarto término van creciendo (calor medio disipado), nos podemos permitir que el primero y el segundo término vayan bajando (aumentando el nivel de complejidad). Se produce así una especie de
adaptación gradual hacia la complejidad a costa de
consumir cada vez más trabajo.
Esta es precisamente la tesis de Jeremy, y es lo que hemos observamos en nuestros estudios de simulación.
En resumen: que es simplemente este proceso
gradual adaptativo (físico y espontáneo) en favor de la
eficiencia en la generación de calor, el que permite observar fenómenos cada vez más organizados y complejos en sistemas lejos del equilibrio térmico. Este proceso de
adaptación natural es, en palabras de
Jeremy, el culpable de cualquier tipo de proceso evolutivo en el Universo, y este proceso de
adaptación natural, es también el que originalmente permitió la organización de ciertas
moléculas en nuestro planeta, y el que terminó al cabo de millones de años dando lugar a la vida en la Tierra.
Además, esta
tendencia física que
correlaciona complejidad y consumo energético, debe
obligatoriamente cumplirse en
cualquier fenómeno macroscópico complejo del mundo, puesto que todo fenómeno se basa en una
física subyacente. Por lo tanto, se puede concluir que
todo fenómeno complejo existe gracias a (y se fundamente en)
consumir y
devorar energía. Y esto incluye, por supuesto, al hombre y a toda su conducta.
Se puede leer un resumen mucho más amplio y explicativo de esto último que he comentado en
esta otra entrada de mi
blog.
Código fuente de los experimentos.
Si alguien está interesado en estudiar más a fondo los ejemplos propuestos, me podéis pedir en un comentario en esta misma entrada el código fuente del programa que he desarrollado para realizar las pruebas que he descrito.
Simplemente es requisito que sepáis programar en
Java, que instaléis el
Eclipse en vuestro ordenador
, y que importéis la librería
Opensourcephysics. Finalmente sólo deberéis importar en el
workspace los ficheros java que yo os pasaré por correo, y ya podréis hacer todas las pruebas que queráis modificando los parámetros de configuración ;).
Aquí tenéis todas las referencias necesarias para seguir este interesante asunto:
- http://www.englandlab.com/publications.html (web oficial del equipo de investigación de Jeremy England. Aquí irán subiendo los avances que se produzcan en este asunto).
- G. E. Crooks, Phys. Rev. E 60, 2721 (1999). [3] R. A. Blythe, Phys. Rev. Lett. 100, 010601 (2008). (Este estudio de Crooks, es el que sirve de base para todo el trabajo de Jeremy).
- Perunov, N., Marsland, R., and England, J. "Statistical Physics of Adaptation", (preprint), arxiv.org, 2014. (Este es el paper de diciembre que ha levantado tanta expectación).
- England, J. L. "Statistical Physics of self-replication." J. Chem. Phys., 139, 121923 (2013). (Este es un paper del 2013, donde el equipo comenzó a dar forma definida a toda la línea de investigación).
- https://www.youtube.com/watch?v=e91D5UAz-f4#t=1720 (Vídeo con una charla del propio Jeremy England donde explica la línea de investigación).
- http://www.scientificamerican.com/article/a-new-physics-theory-of-life/ (Artículo divulgativo en la revista Scientific American sobre el trabajo de Jeremy England).
-
- Artículo donde explico en detalle qué es un algoritmo evolutivo: http://quevidaesta2010.blogspot.com.es/2011/08/computacion-evolutiva-ejemplo-i.html
- Artículo divulgativo, donde explico en más profundidad las implicaciones del trabajo teórico de Jeremy England: http://quevidaesta2010.blogspot.com.es/2015/02/las-matematicas-de-la-conducta.html
- http://quevidaesta2010.blogspot.com.es/2014/12/las-matematicas-de-la-vida.html
- http://quevidaesta2010.blogspot.com.es/2015/01/las-matematicas-de-la-vida-ii.html
- http://quevidaesta2010.blogspot.com.es/2015/01/las-matematicas-de-la-vida-iii.html
- http://quevidaesta2010.blogspot.com.es/2015/01/las-matematicas-de-la-vida-iv.html
- http://quevidaesta2010.blogspot.com.es/2015/01/las-matematicas-de-la-vida-v.html
- Librería de código abierto para la simulación de sistemas físicos: Opensourcephysics
- Enlace externo donde se explica en qué consiste y qué es el potencial de Lennard-Jones.