Cómo vimos en mi anterior artículo, la computación evolutiva tiene un enorme potencial que, en mi opinión, aún no ha sido suficientemente explotado. Y aunque es cierto que se utiliza con frecuencia para aplicaciones dentro de la inteligencia artificial, su uso podría llegar a ámbitos mucho más diversos. Me gustaría, por lo tanto, aprovechar esta entrada (ahora que ya tenemos una idea de lo que es la computación evolutiva), para mostraros un simple ejemplo práctico que demuestre la gran utilidad que este tipo de procesos computacionales puede tener:
Buscando patrones útiles.
Como ya vimos un ejemplo práctico de computación evolutiva y explicamos su funcionamiento interno, vamos a intentar darle una utilidad práctica a dicho ejemplo. En concreto, el programa de ejemplo era una aproximación numérica a la interpolación de una función desconocida a partir de un conjunto dado de datos.
Vamos por lo tanto a basarnos en esta cualidad del programa, para intentar encontrar patrones desconocidos a partir únicamente de ciertos datos empíricos conocidos. En muchas ocasiones, encontrar este patrón es imposible analíticamente, o si no es imposible, casi siempre es muy laborioso, requiriendo de complejos cálculos.
Un ejemplo de esto que digo puede ser el caso de intentar descubrir el patrón real que hay detrás del crecimiento de la población de un país. En el transcurso de los años, la población no crece o decrece de un modo aleatorio o caótico, sino que, a la vista de los datos, parece seguir cierto patrón o comportamiento. En principio este comportamiento del crecimiento de la población es desconocido, y sólo tenemos los datos empíricos de la población de un conjunto de años (los censos).
Según datos proporcionados por Funk & Wagnalls, el censo de Estados Unidos fue desde 1790 hasta 1990 el siguiente:

Realmente nos gustaría, a partir de estos datos, encontrar cual es el patrón oculto que dirige el crecimiento de la población para así, por ejemplo, poder estimar con cierta seguridad, cual será la población en el 2050 (año para el cual evidentemente aún no tenemos datos xD)
La búsqueda de este patrón es un ejemplo usualmente utilizado en la enseñanza universitaria para explicar al alumnado el concepto de ecuación diferencial. Pero para solucionar algún problema usando ecuaciones diferenciales, primero nos encontramos con el problema de conseguir modelar la situación usando ecuaciones en diferencia, luego nos encontramos con el problema frecuente de buscar el valor adecuado para los posibles parámetros usado en el modelo, y finalmente nos encontramos con el problema de encontrar una solución particular para esa ecuación diferencial a partir de ciertas condiciones iniciales.
Por ejemplo, mediante ecuaciones diferenciales se puede hacer un primer intento de modelado del patrón detrás del crecimiento de la población como este:

Este primer intento de modelo es fácil de calcular, y tiene, como solución analítica:
P(t) = 3.9 * e^(0.003067*t)
pero cuando se contrasta esta función con los datos, vemos que el error cometido es grande a partir de cierto valor, por lo que finalmente no es un modelo que satisfaga el patrón oculto al crecimiento de la población.

¿Qué hacemos entonces? Pues buscar un nuevo modelo, solucionarlo y comprobar su nivel de aproximación con los datos.
Para este problema concreto, se suele utilizar un modelo llamado modelo logístico de la población, que viene a ser como el anterior, simplemente añadiendo un nuevo parámetro N que hace referencia a la capacidad de soporte del medio. De este modo, el modelo revisado es:
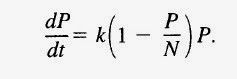
Esta ecuación diferencial ya no es lineal, y su resolución es más compleja, además de que ahora debemos conjeturar el valor de un nuevo parámetro N (además de k).
Este modo de actuar por ensayo y error de modelos es bastante complejo, laborioso y pesado. Para muchos problemas puede ser incluso un método inviable de actuación.
Resolución evolutiva.
¿Qué tal un método sencillo y universal? Un método que no requiera ni siquiera saber qué es una ecuación diferencial y que no necesite que tengamos que conjeturar con modelos para cada problema particular. Este método existe, y consiste simplemente, como seguro ya habréis podido imaginar, en el uso de un algoritmo de computación evolutiva.
La cuestión se reduce de este modo a introducir los datos empíricos en el programa, y a esperar a que el proceso evolutivo encuentre la función que mejor aproxime cada punto. Una vez alcanzada tal función con el nivel de aproximación especificado a priori, podemos estar seguro de que será una buena aproximación al patrón oculto a los datos empíricos de partida.
Posteriormente, simplemente tenemos que probar el patrón alcanzado con datos conocidos pero no pasados al programa (para asegurarnos de su fiabilidad), y finalmente, si la fiabilidad es buena, realizar predicciones para situaciones desconocidas utilizando este patrón hallado.
Aplicación práctica real al caso de estudio del crecimiento de la población de Estados Unidos.
Vamos a hacer uso de la aplicación que desarrollé para el artículo anterior. Como datos de entrada, vamos a introducir los datos facilitados por Funk & Wagnalls del censo de Estados Unidos desde 1790. Para poder estudiar la fiabilidad, no incluiremos las décadas posteriores a 1990. Por lo tanto la entrada del programa quedaría así:
Pulsamos en el botón "Ejecutar el proceso evolutivo" y esperamos las generaciones necesarias hasta que el error de interpolación de los puntos sea inferior a 10.{"x": 0} = 3.9;{"x": 10} = 5.3; {"x": 20} = 7.2; {"x": 30} = 9.6; {"x": 40} = 12;{"x": 50} = 17; {"x": 60} = 23; {"x": 70} = 31;{"x": 80} = 38;{"x": 90} = 50;{"x": 100} = 62;{"x": 110} = 75;{"x": 120} = 91;{"x": 130} = 105;{"x": 140} = 150;{"x": 150} = 131;{"x": 160} = 151;{"x": 170} = 179;{"x": 180} = 203;{"x": 190} = 226;{"x": 200} = 249;error_max = 10
Cuando yo hice la prueba, el proceso terminó tras 271 generaciones, y me ofreció la siguiente función como resultado:

Es una función intimidante, ¿verdad? No te preocupes, es solo que el proceso evolutivo no busca, como puede hacer el científico humano, la sencillez algebraica. No la necesita. Y por eso esta función nos puede parecer extraña y difícil de entender. Pero es que realmente no necesitamos "comprender" el patrón encontrado, sino simplemente utilizarlo para realizar predicciones fiables con él.
Quizás este resultado sea después de todo una solución particular (o una aproximación) para el modelo logístico de la población que vimos antes, con un par de parámetros k y N desconocidos. O quizás no lo sea. No lo sabemos, pero tampoco lo necesitamos saber. Basta con que el patrón sea fiable.
¿El modelo encontrado es fiable?
Vamos a comprobarlo mediante su contrastación con otros datos conocidos pero que no han sido facilitados al programa.
El valor para las décadas posteriores a 1990 no fue facilitado precisamente con este propósito.
Pero primero veamos como se ajusta la función hallada a los datos facilitados al programa:
Año 1830 (t = 40): Valor predicho: 11,973 millones, Valor real: 12 millones, Error: 0,027
Año 1920 (t = 130): Valor predicho: 105,169 millones, Valor real: 105 millones, Error: 0,169
Año 1960 (t = 170): Valor predicho: 178,937 millones, Valor real: 179 millones, Error: 0,063
Se puede comprobar que existe un ajuste extraordinario.
Veamos, a continuación, cómo se ajusta la función a datos no facilitados al programa, pero que son conocidos empíricamente por otros medios. Como la tabla facilitada por Funk & Wagnalls no ofrece más información, usaremos otra fuente de datos alternativa. En concreto, vamos a usar los valores censales de Estados Unidos ofrecidos por la siguiente página web: http://www.datosmacro.com/demografia/poblacion/usa
Tenemos que tener en cuenta, sin embargo, un factor de corrección entre los datos facilitados por Funk & Wagnalls y los ofrecidos por la página web. Existe una variación entre las fuentes de datos de alrededor de un par de millones de habitantes de media. Por lo tanto, cuando usemos nuestra función para comprobar su fiabilidad con los datos de la web, debemos tener en cuenta estos 2 millones de diferencia (al alza o a la baja) entre losestimado por la función y el dato empírico ofrecido por la web datosmacro.
Teniendo esto en cuenta, hacemos las siguientes pruebas con datos no proporcionados al programa:
Año 1975 (t = 185): Valor predicho: 215,206, Valor real: 215,973 +- 2, Error: -0,767 +- 2
Año 1985 (t = 195): Valor predicho: 241,201, Valor real: 238,410 +- 2, Error: 2,791 +- 2
Año 1995 (t = 205): Valor predicho: 263,933, Valor real: 266,458 +- 2, Error: 2,525 +- 2
Año 2000 (t = 210): Valor predicho: 277,575, Valor real: 282,296 +- 2, Error: 4,721 +- 2
Año 2005 (t = 215): Valor predicho: 291,481, Valor real: 296,115 +- 2, Error: -4,634 +- 2
Año 2010 (t = 220): Valor predicho: 303,252, Valor real: 309,761 +- 2, Error: -6,509 +- 2
Año 2015 (t = 225): Valor predicho: 317,500, Valor real: 319,047 +- 2, Error: -1,547 +- 2
Teniendo en cuenta que gran parte del error cometido es probable que se deba al desajuste entre los datos de Funk & Wagnalls y los datos de la web, posiblemente el error medio cometido por la función cuando se contrasta con datos no usados en el proceso de interpolación esté alrededor de entre uno o dos millones. Este error medio, cuando hablamos de cientos de millones de personas, es bastante aceptable, y nos ayuda sin duda a hacernos una idea bastante ajustada de la población de Estados Unidos en cualquier año pasado o futuro (en el futuro será útil siempre que alguna catástrofe muy acusada no modifique el patrón seguido por el crecimiento real hasta ahora).
Predicciones futuras según el modelo.
¿Qué nos deparan las futuras décadas en cuanto a crecimiento de población en Estados Unidos se refiere? Pues, como digo, si no ocurren catástrofes apocalípticas no contempladas por el proceso tales como una epidemia o una guerra nuclear que aniquile a una gran parte de la población (modificando por lo tanto radicalmente el patrón real subyacente), el número de habitantes será con bastante seguridad el siguiente (con un error probable de un par de millones hacia arriba o abajo):
Año 2020 (t = 230): 332,981 millones de habitantes.
Año 2030 (t = 240): 354,429 millones de habitantes.
Año 2040 (t = 250): 387,272 millones de habitantes.
Año 2050 (t = 260): 425,315 millones de habitantes.
Año 2100 (t = 290): 526,467 millones de habitantes.
Año 2500 (t = 690): 3071,513 millones de habitantes.
Dentro de 5 años (ahora mismo estamos en el 2015), podremos comprobar la primera previsión y ver qué error cometió la estimación de nuestro modelo hallado ;).
Si se mantiene el patrón real seguido por Estados Unidos hasta ahora, vemos que pasarán muchas décadas antes de que alcance los 1000 millones de habitantes que tiene China hoy día.
Resumen.
Hemos visto un nuevo ejemplo del potencial que guarda la computación evolutiva. En este caso, hemos estudiado como ofrece una capacidad asombrosa en el descubrimiento de patrones ocultos; patrones que pueden ser demasiado complejos o caóticos para un estudio tradicional, pero que son perfectamente abordables mediante esta interesante y útil técnica de computación.
Hijole, graciaaas por tu publicación, realmente es muy prometedora esta técnica, estoy que salto de la emoción jajajajaj. gracias de nuevo y muy interesante tu blog =)
ResponderEliminarMuy buena infamación me ayudo a comprender varios aspectos diferentes que no conocía Gracias
ResponderEliminarExcelente información, relacionas algunos términos que casi no se profundizan, y es de gran ayuda conocerlo, Gracias.
ResponderEliminar